It doesn’t have much to do with topology, but I’d like to share with you something Avishy Carmi and I have been thinking about quite a bit lately, that is the EPR paradox and the meaning of (non)locality. Avishy and I have a preprint about this:
A.Y. Carmi and D.M., Statistics Limits Nonlocality, arXiv:1507.07514.
It offers a statistical explanation for a Physics inequality called Tsirelson’s bound (perhaps to be compared to a known explanation called Information Causality). Behind the fold I will sketch how it works.
Information about a parameter though a binary channel
A binary channel is a pair of Bernoulli (




Usually it is a realization of ![\theta_X= E[X]](https://s0.wp.com/latex.php?latex=%5Ctheta_X%3D+E%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002)

I would like to partition what may happen into three (realistic) cases:
- There is no channel between
. A fortiori, a finite number of samples of
- There is a channel between
, but what is being broadcast through the channel cannot be distinguished from noise. More precisely, consider Fisher Information that is a mathematical quantity measuring how much samples of a random variable tells us about a parameter. It measures this via the Cramér-Rao Theorem, which tells us that the variance of any estimate which Bob can construct of
-valued random variables have variance bounded above by
(the variance of a Bernoulli random variable is
whose maximum us at
is `no information’. Thus Bob would learn just the same about Alice’s variable by tossing a fair coin as he would learn by listening to the output of the channel.
- Alice and Bob are communicating!
I would like to draw your attention to the second case, in which there is a channel but the information broadcast through the channel is indistinguishable from noise. The situation is analogous to a long game of Chinese whispers, in which one person whispers a message to another until the final person announces the message to the entire group. A massive such game played in 2012 resulted in “Alice’s” message “Life must be lived as play” (a paraphrase of a quote from Plato) being relayed to “Bob” as “He bites snails”. In a long enough game, with probability one, Bob will receive only noise despite a channel undeniably existing.
In a certain context, Physicists refer to Case I (nonexistence of a channel) as “Locality”, in that Alice and Bob are effectively isolated from one another. But I think that Case II is also “Locality” according to my intuitive understanding of the term. If a tree falls in a forest and no one is around to hear, does it make a sound? If a sample of
But the word “Locality” is taken to refer to Case I, therefore I’ll refer to Cases I and II together (in the physical context I’m just about to describe) as “Information Locality”.
Physical context
In Newtonian Mechanics an object can only be in one place at one time. An arresting feature of Quantum Mechanics is there is a sense in which an object can be located in two places at once. More precisely:
Nonlocality: A pair of quantum systems which are shown not to be physically interacting may be impossible to describe as independent entities.
Such a pair of unseparable quantum systems perforce must be described as one system system which is in two places at once. The archetype of nonlocality is a pair of distant agents Alice and Bob each of whom hold one half of a singlet. A measurement performed on Alice’s particle appears to have an instantaneous effect on Bob’s particle and vice versa. The strength of this perceived effect is quantified by a real number 


Bell’s Theorem is proved using only Probability Theory and as such is independent of the functional analysis formalism of Quantum Mechanics. Why is this important? Besides aesthetic considerations, reliance on Probability Theory alone is good in the context of a search for a Grand Unified Theory to unify Quantum Mechanics with General Relativity. But the mathematical formalism of Quantum Mechanics (functional analysis) is different from the mathematical formalism of General Relativity (differential geometry). Thus, we would expect a grand unified theory to be described by a mathematical formalism which envelopes both of these formalisms and more, and in particular we would not expect it to be based on functional analysis.
Bell’s Inequality is indeed violated experimentally. Nonlocality is real. Newtonian mechanics alone cannot describe the quantum world.
How large can 
Within the Hilbert-space formalism of quantum mechanics, Tsirelson showed that 
We would love to understand Tsirelson’s bound in a broader context (e.g. probability or statistics), so that the same upper bound on 
Channels from Bell experiments
The basic building block of the so-called “context-free approach” to nonlocality is a pair of boxes, one held by Alice and one by Bob. These boxes abstract the notion of entangled particles. Into each box you can insert either a zero or a one, and the box responds by instantaneously spitting out either a zero or a one. Call Alice’s box input 





The Bell-CHSH correlation

Thus, 
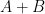
Having noted that
The classical protocol for multiple boxes is called an “oblivious transfer” and is detailed in a paper by van Dam. Alice and Bob each hold in front of them an infinite family of boxes, such that each box of Alice’s is correlated with a box of Bob’s with Bell-CHSH parameter ![\theta_X\in [-1,1]](https://s0.wp.com/latex.php?latex=%5Ctheta_X%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)



We specialize to the case 





Results
Almost all of our actual work was figuring out the reformulation above- with everything well-defined and phrased in terms of channels, the computations are routine.
A quick computation shows that 





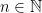

[Note that we’re assuming that 
In other words, within the context of the oblivious transfer protocol, Tsirelson’s bound is interpreted as a necessary and sufficient condition for information locality. This interprets Tsirelson’s bound entirely in terms of statistics.
Note that if Tsirelson’s bound were violated we would have a strange “Case 4” (which is actually Case I and Case III at once) in the
A concrete thought experiment
Informally, our result states that Bob may infer nontrivial information about
Let’s consider the special case in which either 

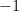
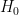
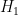
A computation shows that the likelihood ratio in this case is asymptotically 

Relationship to Information Causality
Our result is related to a known criterion called Information Causality. Is it sufficiently novel compared to this criterion? I can’t express an opinion… “sufficiency of novelty” isn’t well-defined. Below I describe the relationship of our work with Information Causality.
The original paper which formulated Tsirelson’s bound in terms of information was Information Causality as a Physical Principle by Pawlowski, Paterek, Kaszlikowski, Scarani, Winter, and Zukowski. In the same context as the one we work in, that paper formulates a principle called Information Causality, which roughly states that the maximum information Bob can have about Alice’s bits is
Here is a rough formulation of Information Causality:
Information Causality: The amount of information potentially available to Bob about Alice’s bits is bounded above by the number of bits Alice sends to Bob through a classical channel.
And here, beside it, is a formulation of the principle we would like to suggest instead.
Statistical No-Signaling: No information can pass through a channel whose output is independent of its input (Case I).
This is equivalent to Tsirelson’s bound via the 
The “Information Causality quantity” is the mutual information of
Concretely, the information causality quantity is less than or equal to a term which we interpret as Fisher information, which is less than or equal to
In the appendix to their paper:

In what sense, then, is our result more than a trivial restatement of Information Causality? Well, first of all, it’s technically a different mathematical result. It implies information causality (in the context of the protocols we both consider, anyway) but is not implied by it in any obvious way.
Perhaps I can argue that Statistical No-Signaling is more fundamental. Information causality involves a whole Alice-and-Bob story (and I’m not sure how to formulate it rigourously mathematically), whereas Statistical No-Signaling is a general statistical statement- if
Our `story’ is different also. We’ve interpreted the intermediate term as Fisher information so that the task we are discussing is a statistical inference task as opposed to measuring mutual information between two strings. So, for us, Tsirelson’s bound is related to the Central Limit Theorem, by which we can characterize the convergence the sample mean of
Because the CLT is so mathematically fundamental, many criteria can be formulated that will follow from it. Actually I think that Statistical No-Signaling might philosophically be closer to Macroscopic Locality than to Information Causality, because we’re saying that a physical system `becomes local’ as the number of boxes grows to infinity. I don’t know how to rigourously derive Macroscopic Locality from our work though.
Still on the `story’ front, Fisher information gives us the 3-way division discussed at the beginning of this post, interpreting the three relevant ranges of the Bell-CHSH parameter 


In addition, functionally, we have a thought experiment with a binary outcome which succeeds if and only if Tsirelson’s bound is violated, and I’m not sure how you could do that with Information Causality.
Why I care
So why would I (D.M.) be looking at physics-y things like this?
Well, personally I think that the fundamental laws of nature ought to be distributive and nonassociative (this is an irrational bias, I know). One thing that this implies to me is that we should attempt to work as much as possible at the level of measures of information (e.g. Fisher information) rather than working in terms of vectors, functions, strings, and so on. We’ve worked on understanding information flow in a low dimensional topological context in previous work, such as arXiv:1409.5505.
I’d like to suggest the philosophical idea that joint distributions are largely a fiction. We can’t meaningfully speak about joint distributions of distant objects we can’t instantaneously compare. But marginals- conditional probabilities- are real. Nonlocality is a setting in which that is how things work. Estimators based on conditional probabilities behave like quandle elements (that’s in arXiv:1409.5505), so my dream is to link this all up to low-dimesional topology. But I’m not there yet.
Final word
If you want to know more, please read the preprint. Feedback is welcome!!

[…] 关于量子非定域性 (non-locality),Bell-CHSH不等式和Tsirelson上界,有一篇很重要的文章,第一次给出了一个等价于Tsirelson上界的物理原理,即所谓的statistical no-signaling principle: Carmi, Moskovich Statistics Limits Nonlocality 一个面向一般大众的介绍可以在这里找到。 […]
Pingback by 月旦 I | Fight with Infinity — March 4, 2016 @ 8:05 am |
Reblogged this on Braveheart.
Comment by PerryZhao — March 6, 2016 @ 8:22 am |