In this post, I continue my series on the topology of large data sets and, in particular, I will finally get to some topology. In my last few posts, I have tried to make the point that many of the widely used approaches to analyzing large sets of high dimensional data are only equipped to handle data that adheres to relatively simple, essentially linear models. While there are some methods for generalizing the algorithms to non-linear data sets (I mentioned kernels as one example) choosing the right method requires that you know something about the large scale structure of the data. In this post, I will discuss one approach to discovering the large scale topological structure, namely persistent homology. (For any readers who who are coming from the data mining side of things: I will assume below that the reader knows what homology groups are. If you don’t, you should still read on, but I’ll refer you to one of the books here or here for the details.)
A finite set of points, no matter how large, has a very boring topology. But if we were to put a ball of some fixed radius around each point, things might start to get more interesting. (We’re thinking of a finite set of points in a finite dimensional Euclidean space.) If the radius of the balls is too small, then the resulting topological space is a collection of disjoint balls, and if the radius is too big then it’s (topologically) just one big ball. In between these two extremes, however, the resulting sets will likely have very interesting topological structures, though the structure will depend heavily on the radius. If the points are sampled from a topologically interesting distribution then some of the features of the intermediate structures will be caused by the structure of the distribution and some will be caused by noise. The philosophy behind persistent homology is that whichever parts of the topological structure are present for large ranges of radius values are probably caused by the structure of the distribution, so we should look for ways to measure how persistent the different topological features are.
Here’s how one makes this rigorous: A persistent complex is a simplicial complex 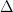







So this persistent complex is roughly the dual skeleton of the union of the balls described above. (It’s not exactly the same, but I’ll leave that to the reader to figure out why not.) There are more complex ways to define a persistent complex from a data set, such as the witness complex(PDF), but lets not worry about that right now. The important point is that once we have a simplicial complex, we can calculate its homology.
In fact, we have a sequence of homology groups, one for each complex in the nested sequence. We want to determine when an element of one of these homology groups “persists” through a long subsequence of the homology groups. The inclusion maps between the complexes define homomorphisms between the groups and that lets us talk about elements of different groups being the same. So we want to see how long each element lasts before its image under an inclusion map is trivial. However, our homology groups are generally going to be infinite and the inclusion homomorphisms generally won’t be injective or surjective so it seems like we’re going to end up with a big complicated mess. What saves us is a theorem of Zomorodian and Carlsson [1] that says we can find a basis for the sequence of homology groups, analogous to a basis for an abelian group: Each element has a beginning time and an ending time and the homology group at time
This structure is often drawn as a collection of horizontal bars, whose left and right borders represent their beginning and ending times on a horizontal scale, arranged vertically by their beginning time. This figure is called a barcode and gives a nice visual description of the topology of the data set. Longer bars represent homology elements that persist through a wide range of time and therefore probably represent structural features, while short bars probably correspond to noise. (Determining how long is long enough to suggest that a bar isn’t noise is a wide open problem.)
This basic idea has been generalized in a number of ways (including zig-zag persistence, which allows one to drop the requirement that the sequence of complexes be nested) and applied to a number of real world data sets. I haven’t managed to keep track of all the latest, but Gunnar Carlsson’s website has a continually updated list of papers related to persistent homology as well as links to software and other resources.
But we’re not done yet: Knowing the homology groups of a space tells you what kind of structure is there, but doesn’t necessarily tell you where the structure is. In particular, persistent homology on its own doesn’t give you nice representatives of the persistent elements. In my next post, I will write about some of the methods that have been developed to find more concrete presentations for the topological information that comes from persistent homology.
[1] A. Zomorodian and G. Carlsson, “Computing persistent homology” , 20th ACM Symposium on Computational Geometry . Jun 2004

The way persistent homology is implemented in most of the software packages, you _do_ get — if you really want them — representatives for the persistent elements; what you don’t get (and I suspect you’ll write about) are representatives with any sort of niceness guarantees — for that, Jeff Erickson and many others have work on finding small cycles, and Zomorodian (with Carlsson IIRC) has a paper on _localized persistent homology_ that also tries to find small representatives.
Comment by Mikael Vejdemo-Johansson — June 12, 2012 @ 9:36 pm |
Good point, and you’re right I was trying to motivate the work you mentioned on finding short representatives. I hadn’t seen the localized homology paper, but I’ll take a look at it before I write my next post.
Comment by Jesse Johnson — June 13, 2012 @ 10:17 am |
Interesting posts, Jesse.
In the third (non-parenthetical) sentence of the second paragraph, “two” should be “too”.
Comment by Chris Atkinson — June 15, 2012 @ 8:53 am |
Got it. Thanks!
Comment by Jesse Johnson — June 15, 2012 @ 2:40 pm |
[…] Low dimensional topology continues a series about topology of large data sets. […]
Pingback by Mathblogging.org Weekly Picks « Mathblogging.org — the Blog — June 20, 2012 @ 9:53 pm |