As I mentioned in my previous post, I plan to write a series of posts about study of large data sets, both the ways that high dimensional data has traditionally been studied and the topology that has recently been applied to this area. For anyone who has experience thinking about abstract geometric objects (as I assume most of the readers of this blog do) the concepts should seem pretty straightforward, and the difficulty is mostly in translation. So I will start with a post that focusses on defining terms. (Update: I’ve started a second blog The Shape of Data to look into these topics in more detail.)
You can also skip ahead to later posts in this series:
- The geometry of neural networks
- Principle component analysis
- Making linear data algorithms less linear: kernels
- Topological exploration of data sets: persistent homology
- Refining information from persistent homology
- Finding clusters in data
- Topological Clustering
- Digital spheres and Reeb graphs
The study of large data sets in the abstract generally goes by two names: Data mining is the field that grew out of statistics, which considers ways to organize and summarize high dimensional data so that it can be understood by humans. Machine Learning is the subfield of computer science (particularly artificial intelligence) that looks for ways to have computers organize and summarize data, with the goal of having the computer make decisions. These two fields have a lot in common and I will not try to distinguish between them. There are also names for the application of these methods in different sciences, such as Bioinformatics and Cheminformatics. There are also rather notorious applications in marketing, which allow stores to know what you’re going to buy before you know.
We are given a collection of data, usually a set of ordered n-tuples, that come from a science experiment or surveys, or the data that retailers collect about you every time you use your credit card, etc. Some of the entries can be thought of as labels – the code number for the particular experiment, for example. The remaining coordinates/dimensions are often called features. If these features are numerical, then we can think of them as defining vectors in a Euclidean space, and this gives us our first glimpse of geometry. However, for high dimensional data, the Euclidean metric turns out to be problematic, so we will often want to use a different metric. The Euclidean metric is also problematic for binary features such as the presence of different genes in an organism.
So we will often want to consider other metrics on our data points. A kernel is a non-linear embedding of the original vector space into a higher dimensional vector space, which allows one to use the pullback metric from the image space. In practice, though, the embedding is not calculated, only the induced metric.
It’s also sometimes useful to consider a similarity measure rather than a metric, which ranges from 1 when the two points are the same to 0 when they’re completely different. The Gaussian of the Euclidean metric is a popular similarity measure. There’s also non-numerical data, which can be analyzed using different metrics depending on the situation, but lets not worry about that right now.
We want to think of this data as being randomly selected from a probability distribution on our vector space. This distribution could have a very definite structure, such as being localized around a positive codimensional submanifold, but because of noise in the data, we generally assume that the support of the distribution is an open set. And, of course, we’re not allowed to decide that it’s a discrete distribution supported on the finitely many data points that we’re given. This would be an example of overfitting, which and any model has to avoid.
Here are four relatively concrete ways that researchers attempt to understand large data sets, and some of the more common algorithms that are used. There are lots of variations on these, but this list is at least a good start. I’ll write in more detail about each of them in future posts.
1) Projection – Find a function from the original vector space to a low dimensional space (such as the plane) that distorts the relationships between points as little as possible. Linear projection is, of course, a possibility and figuring out the best linear projection is a non-trivial task. The most popular approach to linear projection seems to be principal component analysis. As topologists, though, we can imagine the potential issues with linear projection, particularly for topologically interesting sets. The self organizing map (sometimes called a Kohonen map) produces a locally/piecewise linear projection that seems much more topologically sound. (Update based on Comment 3:) More generally, one can try to project onto a topologically more interesting low dimensional manifold and this is called manifold learning.
2) Feature Selection and Extraction – With some high dimensional data, many of the dimensions are mostly noise. Feature selection is the problem of figuring out which features have the highest signal/noise ratio. There are statistical methods that examine each feature/dimension individually, but it’s often better to look at subsets of features all at once. Feature extraction is the slightly more general problem of taking linear combinations of features that best amplify the signal over the noise. From the topological point of view, this is just a restricted form of linear projection, but in practice it tends to be a separate type of problem. In particular, one generally wants to project into two or three dimensions, but for feature selection, you’re allowed to select more than two or three features.
Either of these two problems is often a preliminary step to one of the following two:
3) Classification – This problem is most closely associated with machine learning and is generally called supervised learning: Given one collection of data with labels telling you where it came from, and another collection of data without labels, decide what label is most suitable for each element of the second set of points. This is “learning” because you can think of the labeled data as training – you tell the computer what choice to make in each of a set of situations. Then the computer has to decide on its own what to do in the rest of the situations. Often, one wants to build a reasonable model based on the labeled data, then throw out the original data and classify the new points based on the model. In particular, there is often a tradeoff between making a model topologically sophisticated or making it computationally inexpensive. And, as mentioned above, the model must avoid overfitting. There are many different approaches to this problem.
4) Clustering – This is the problem of partitioning (unlabeled) data into a small number of sets based on their geometry. It is the central problem of data mining, though in machine learning it is classified under unsupervised learning, i.e. working with unlabeled data. One popular algorithm for this is K-means, which assumes that the probability distribution is a sum of Gaussians centered at K points and tries to find those points. This algorithm is known for being computationally efficient, but often returning junk results. A more topologically reasonable approach is to form a graph whose vertices are the data points. with edges connecting points whose distance is below a given threshold (or whose similarity is above a given threshold). This translates the clustering problem into a graph partitioning problem – cutting the graph into relatively large pieces by cutting relatively few edges.
These problems are relatively concrete, though unlike the problem we’re used to as topologists, there is no possibility of a definitive, final answer. Instead, the best approach to each problem depends on the specific data set and the long term goals of the analysis. So for any approach, including approaches inspired by topology, there is a reasonable chance that it will be useful in some situation.

Looking forward to your series, Jesse.
Comment by Ryan Budney — April 11, 2012 @ 2:29 pm |
I really enjoyed this post. Thank you.
Comment by Sam Lisi — April 11, 2012 @ 3:46 pm |
I’m really interested in exactly this intersection of topology and statistics (especially what you call “Projection” algorithms, which statisticians more commonly refer to as “Manifold Learning”). Great post!
Comment by Jimmy Jin — April 12, 2012 @ 8:50 am |
That’s a good point. Thanks. I’ll add the term manifold learning under projections. I think persistence homology techniques (http://comptop.stanford.edu) could probably be very useful for manifold learning, and I’ll try to address that in a future post.
Comment by Jesse Johnson — April 12, 2012 @ 10:10 am |
Enjoyed the post. Thanks!
Comment by mlohr — April 12, 2012 @ 9:30 am |
I’m really looking forward to these posts. I recently left my grad school program (in low dimensional and quantum topology) and I’m now right in the middle of this big data and machine learning world. I’m slowly connecting all of my abstract tools to the real world, but this helps a lot. Thanks!
Comment by Brandon — April 14, 2012 @ 1:39 pm |
Reblogged this on Cinna Wu and commented:
Very interesting article on the connections between big data and topology!
Comment by Cinna — April 14, 2012 @ 6:12 pm |
very interesting. wish I knew more about what “non-linear embedding” and “the pullback metric from the image space” mean. fyi, a typo: “overfitting, which and any model has to avoid” (extraneous “and”)
Comment by Andrew — April 19, 2012 @ 2:41 pm |
I’ll write in more detail about kernels in an upcoming post, but here’s a bit more explanation: By non-linear embedding, I mean a function/map from the given vector space into a larger space that isn’t just given by a matrix. So this map will distort the vector space structure. By the pullback metric, I mean that you define the distance between any
any  as the distance between
as the distance between  and
and 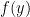 where f is this non-linear map.
where f is this non-linear map.
Comment by Jesse Johnson — April 20, 2012 @ 1:26 pm |
This month’s AMS Notices has a timely “What is data mining?” article: http://www.ams.org/notices/201204/rtx120400532p.pdf
Comment by Ryan Budney — April 20, 2012 @ 2:42 pm |
Very clear and concise overview, thanks for the post Jesse. Maybe I would suggest renaming 2 as feature selection and extraction, which makes it more explicit that you can define new features as (possibly non-linear) combinations of the present ones, instead of just picking a subset.
Comment by Mustafa Ozuysal — March 30, 2013 @ 7:24 am |
Good idea. I think of feature extraction (such as PCA) as a form of linear projection, which is why I didn’t include it originally. But it does make sense to mention it along with feature selection, since it’s a different perspective on the same process.
Comment by Jesse Johnson — March 30, 2013 @ 9:17 am |
[…] Big Data and the Topologist […]
Pingback by Links & reads for 2013 Week 13 | Martin's Weekly Curations — March 31, 2013 @ 5:13 pm |
I can’t read this on my android tablet. There is big honking ‘follow’ window over the lower right corner.
Can you please get rid of that?
Comment by Erik van Oosten (@erik_van_oosten) — April 1, 2013 @ 8:17 am |
The follow button is something that that wordpress recently added, and I don’t think authors of individual blogs have much control over it. You should let wordpress know that there’s an issue with the site on your tablet browser, because this is probably a problem on other blogs as well.
Comment by Jesse Johnson — April 3, 2013 @ 9:17 am |
[…] 原文链接:https://ldtopology.wordpress.com/2012/04/11/big-data-and-the-topologist/ […]
Pingback by 大数据与拓扑学共通的一些分析算法 | 内容采集 — February 2, 2015 @ 12:15 pm |