This is just a quick note that some folks have put together a site call Virtual Low-dimensional Topology “to organize virtual activities related to all facets of low-dimensional topology.” It includes working groups, virtual office hours with topologists, links to seminars, and more!
May 26, 2020
January 1, 2020
Isotopy in dimension 4
Four-dimensional manifold theory is remarkable for a variety of reasons. It has the only outstanding generalized smooth Poincare conjecture. It is the only dimension where vector spaces have more than one smooth structure. The only dimension with an unresolved generalized Shoenflies problem. The list goes on. One issue that is perhaps not discussed enough is the paucity of theorems about smooth isotopy. In dimensions 2 and 3, the Schoenflies and Alexander theorems are the backbone of all theorems about isotopy, allowing one to work from the ground-up.
March 7, 2019
The Topology of Neural Networks, Part 2: Compositions and Dimensions
In Part 1 of this series, I gave an abstract description of one of the main problems in Machine Learning, the Generalization Problem, in which one uses the values of a function at a finite number of points to infer the entire function. The typical approach to this problem is to choose a finite-dimensional subset of the space of all possible functions, then choose the function from this family that minimizes something called cost function, defined by how accurate each function is on the sampled points. In this post, I will describe how the regression example from the last post generalizes to a family of models called Neural Networks, then describe how I recently used some fairly basic topology to demonstrate restrictions on the types of functions certain neural networks can produce.
October 21, 2018
The Topology of Neural Networks, Part 1: The Generalization Problem
I gave a talk a few months ago at the Thompson-Scharlemann-Kirby conference about a theorem I recently proved about topological limitations on certain families of neural networks. Most of the talk was a description of how neural networks work in terms of more abstract mathematics than they’re typically described in, and I thought this was probably a good thing to write up in a blog post. I decided to split the post into two parts because it was getting quite long. So the first post will describe the general approach to defining Machine Learning models, and the second post will cover Neural Networks in particular.
April 4, 2018
Two widely-believed conjectures. One is false.
I haven’t blogged for a long time- for the last few years, my research has been leading me away from low dimensional topology and more towards foundations of quantum physics. You can read my latest paper on the topic HERE.
Today I’d like to tell you about a preprint by Malyutin, that shows that two widely believed knot theory conjectures are mutually exclusive!
A Malyutin, On the Question of Genericity of Hyperbolic Knots, https://arxiv.org/abs/1612.03368.
Conjecture 1: Almost all prime knots are hyperbolic. More precisely, the proportion of hyperbolic knots amongst all prime knots of 
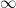
Conjecture 2: The crossing number (the minimal number of crossings of a knot diagram of that knot) of a composite knot is not less than that of each of its factors. (more…)
December 19, 2017
Computation in geometric topology
Complete lecture videos for last week’s workshop Computation in Geometric Topology at Warwick are now posted on YouTube. The complete list of talks with abstracts and video links is here.
September 14, 2017
What is the complexity of the homeomorphism problem?
Homeomorphism Problems are the guiding problems of low-dimensional topology: Given two topological objects, determine whether or not they are homeomorphic to one another. A lot of topology is tangential to this problem- we may define invariants, investigate their properties, and prove relationships between them, but we rarely directly touch on the Homeomorphism Problem. Direct progress on the Homeomorphism Problem is a big deal!
I’m excited by a number of new and semi-new papers by Greg Kuperberg and collaborators. From my point of view, the most interesting of all is:
G. Kuperberg, Algorithmic homeomorphism of
-manifolds as a corollary of geometrization, http://front.math.ucdavis.edu/1508.06720
This paper contains two results:
1) That Geometrization implies that there exists a recursive algorithm to determine whether two closed oriented
2) Result (1), except with the words “elementary recursive” replacing the words “recursive”.
Result (1) is sort-of a well-known folklore theorem, and is essentially due to Riley and Thurston (with lots of subsections of it obtaining newer fancier proofs in the interim), but no full self-contained proof had appeared for it in one place until now. It’s great to have one- moreover, a proof which uses only the tools that were available in the 1970’s.
Knowing that we have a recursive algorithm, the immediate and important question is the complexity class of the best algorithm. Kuperberg has provided a worst-case bound, but “elementary recursive” is a generous computational class. The real question I think, and one that is asked at the end of the paper, is where exactly the homeomorphism problem falls on the heirarchy of complexity classes:
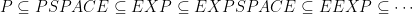
And whether the corresponding result holds for compact
March 18, 2017
A new “Mathematician’s Apology”
In the two and a half years (or so) since I left academia for industry, I’ve worked with a number of math majors and math PhDs outside of academia and talked to a number of current grad students who were considering going into industry. As a result, my perspective on the role of the math research community within the larger world has changed quite a bit from what it was in the early days of may academic career. In the post below, I explore this new perspective.
March 3, 2017
Office House with a Geometric Group Theorist
It’s hard enough for one author to write a coherent work; for many authors, even if it’s one and the same topic one might end up with Rashoumon (in the sense of different and contradicting narratives). But, as the Princeton Companion to Mathematics shows, it is possible to have a coherent book with each author writing a chapter, and now geometric group theory has one too.
A new book has just come out, and it’s very good.
Office Hours with a Geometric Group Theorist, Edited by Matt Clay & Dan Margalit, 2017.
An undergraduate student walks into the office of a geometric group theorist, curious about the subject and perhaps looking for a senior thesis topic. The researcher pitches their favourite sub-topic to the student in a single “office hour”.
The book collects together 16 independent such “office hours”, plus two introductory office hours by the editors (Matt Clay and Dan Margalit) to get the student off the ground. (more…)
