I will continue my series of posts on the geometry and topology of big data with a description of principle component analysis (PCA), a technique from the statistics side of data analysis. Like my last post, there will be nothing explicitly related to or drawn from low dimensional topology, but bear with me. After a few more posts about the standard approaches to these problems, I will address how ideas drawn from topology can be applied to these sorts of problems. As mentioned before, I believe these applications have the potential to enrich the pure field with new problems and new techniques.
In statistics, given a set of numbers  with mean 0, the variance of the set is the sum
with mean 0, the variance of the set is the sum  . This measures the how tightly packed the numbers are around 0. Given a set of vectors, we can calculate the variance in each dimension, i.e. we think of all the values in the first place of the different vectors and calculate the variance of this set. (We will assume that the vectors have been translated so that the mean in each dimension is zero.)
. This measures the how tightly packed the numbers are around 0. Given a set of vectors, we can calculate the variance in each dimension, i.e. we think of all the values in the first place of the different vectors and calculate the variance of this set. (We will assume that the vectors have been translated so that the mean in each dimension is zero.)
For a set of two-dimensional vectors 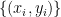 , the covariance of the two dimensions is
, the covariance of the two dimensions is 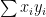 . This measures how evenly distributed the values are between the two dimensions, or how likely it is for
. This measures how evenly distributed the values are between the two dimensions, or how likely it is for 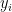 to be large when
to be large when  is large, etc. For any set of
is large, etc. For any set of  dimensional vectors, we can calculate the covariance for any pair of dimensions, and we can think of the results as an
dimensional vectors, we can calculate the covariance for any pair of dimensions, and we can think of the results as an 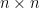 matrix (with the variance of each dimension down the diagonal), called the covariance matrix.
matrix (with the variance of each dimension down the diagonal), called the covariance matrix.
If we think of the set of  vectors of dimension as a
vectors of dimension as a 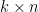 matrix
matrix  , then the covariance matrix is the product
, then the covariance matrix is the product  of with its transpose. Because of this definition, the reader can check that if we apply a basis change to the vectors, defined by a matrix
of with its transpose. Because of this definition, the reader can check that if we apply a basis change to the vectors, defined by a matrix  , then the covariance matrix becomes
, then the covariance matrix becomes 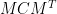 (where
(where  is the transpose.)
is the transpose.)
Since is a symmetric matrix, we can find a matrix so that is a diagonal matrix, i.e. all the covariances are zero. So in this new basis for the data vectors, the data is “evenly balanced” between the variables. The intuition from the statistical point of view is that the new basis vectors (which are eigenvectors of ) are the main axes (i.e. the principle components) of the set of data. In particular, this is the case if you take a Gaussian distribution and apply a linear transformation that stretches it more in some directions than in others.
The eigenvalues of , which are the diagonal entries of , give you the variance along the main axes, i.e. how much the data is stretched in that direction. So the way that this is most often used is to orthogonally project onto the largest few principle components. In particular, if there is a sudden drop off in the eigenvalues – the first few eigenvalues are much larger than the later ones – this suggests that the data set is very flat in most directions, so we should project onto the eigenvectors corresponding to the larger eigenvalues. For visualization, however, it is more common to project onto the two eigenvectors with the largest eigenvalues, regardless of how large the remaining eigenvalues are. As you can imagine, this has the potential to greatly distort the picture.
As a topologist, of course, you should be skeptical that it is a good idea to restrict oneself to linear projection, particularly when projecting from lots of dimensions down to 2. The main advantage of this type of method is that it uses basic linear algebra operations and is thus very computationally efficient. I will discuss in my next post a trick called a kernel that can be used to make algorithms like PCA less linear without giving up to much computational efficiency.

I think you want to say “eigenvectors of C” and “eigenvalues of C” instead of “eigenvectors of M” and eigenvalues of C”, i.e., PCA is essentially the spectral decomposition of the covariance matrix (M in this case is the matrix of eigenvectors)
Comment by hrf — March 30, 2013 @ 8:20 am |
Good call. Thanks! (It’s fixed now.)
Comment by Jesse Johnson — March 30, 2013 @ 9:19 am |